AI Speech Engineer Roadmap: From Zero to Production in 18 Months
A curated 18-month learning roadmap for becoming an AI Speech Engineer — covering foundations, core technologies (ASR, TTS, Speaker Verification, Diarization, Voice Conversion), and the latest Audio Language Models, distilled from 6 years of hands-on experience.

Why Do Language Models Hallucinate?
An analysis of why language models hallucinate — hallucinations arise from statistical pressures in training and evaluation procedures that reward guessing over acknowledging uncertainty.

Writing technical content in Academic
A guide to writing technical content in Academic — highlighting code snippets, rendering math equations, and drawing diagrams from text.

Speaker Diarization: From Traditional Methods to the Modern Models
Speaker Diarization answers “Who spoken when?” — covering core concepts, traditional and modern end-to-end approaches, and the latest Sortformer model for speaker segmentation.

Why Entropy Matters in Machine Learning?
Understanding entropy and why it’s a core concept in decision trees, neural networks, and loss functions like cross-entropy.

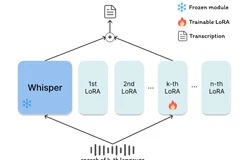
LoRA-Whisper: A Scalable and Efficient Solution for Multilingual ASR
Exploring LoRA-Whisper, a scalable and efficient approach for multilingual ASR using Low-Rank Adaptation to fine-tune OpenAI’s Whisper model while avoiding catastrophic forgetting across languages.
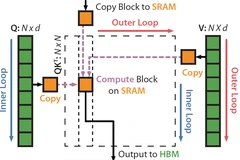
Understanding FlashAttention: Inner vs Outer Loop Optimization
FlashAttention is a groundbreaking optimization technique for computing attention in Transformer models, drastically improving GPU memory efficiency through inner vs outer loop restructuring.
Adversarial Attacks on Large Language Models (LLMs)
An overview of adversarial attacks on large language models (LLMs) — how manipulated inputs can deceive models into generating harmful or incorrect outputs, covering key attack types, implications, and defense strategies.

GLiNER: A Generalist Model for Named Entity Recognition using Bidirectional Transformers
A detailed summary of the GLiNER paper, introducing a lightweight, scalable, and highly effective model for open-type named entity recognition using bidirectional transformers with zero-shot generalization.

Handy Bash Snippets and Linux Tips
A curated collection of bash functions, troubleshooting commands, and performance tweaks that I often use in my daily workflow.
