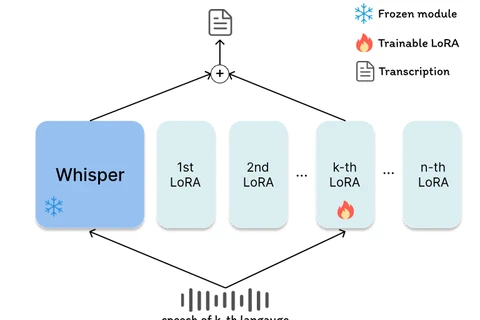
LoRA-Whisper: A Scalable and Efficient Solution for Multilingual ASR
Exploring LoRA-Whisper, a scalable and efficient approach for multilingual ASR using Low-Rank Adaptation to fine-tune OpenAI’s Whisper model while avoiding catastrophic forgetting across languages.
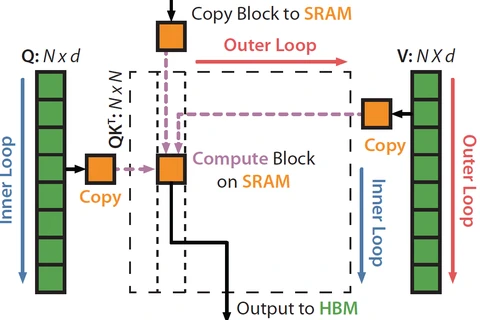
Understanding FlashAttention: Inner vs Outer Loop Optimization
FlashAttention is a groundbreaking optimization technique for computing attention in Transformer models, drastically improving GPU memory efficiency through inner vs outer loop restructuring.
Adversarial Attacks on Large Language Models (LLMs)
An overview of adversarial attacks on large language models (LLMs) — how manipulated inputs can deceive models into generating harmful or incorrect outputs, covering key attack types, implications, and defense strategies.

GLiNER: A Generalist Model for Named Entity Recognition using Bidirectional Transformers
A detailed summary of the GLiNER paper, introducing a lightweight, scalable, and highly effective model for open-type named entity recognition using bidirectional transformers with zero-shot generalization.
Handy Bash Snippets and Linux Tips
A curated collection of bash functions, troubleshooting commands, and performance tweaks that I often use in my daily workflow.

Vietnamese Voice Conversion
Overview
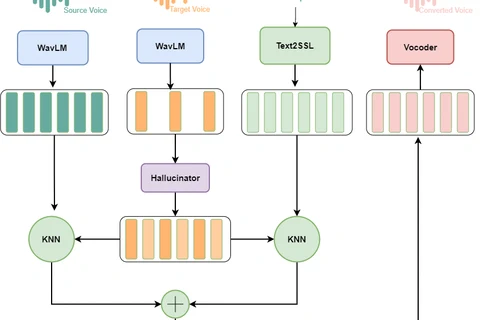
This thesis develops a voice conversion model for Vietnamese based on the Phoneme Hallucinator model with 2 adoptions: (1) Add a Text2SSL module to get more context information before performing the KNN algorithm, (2) To create a more
diverse dataset we apply spectrogram-resize (SR) based data augmentation idea from Free-VC model which distorts speaker information without changing content information to generate more ”speakers”.
The proposal model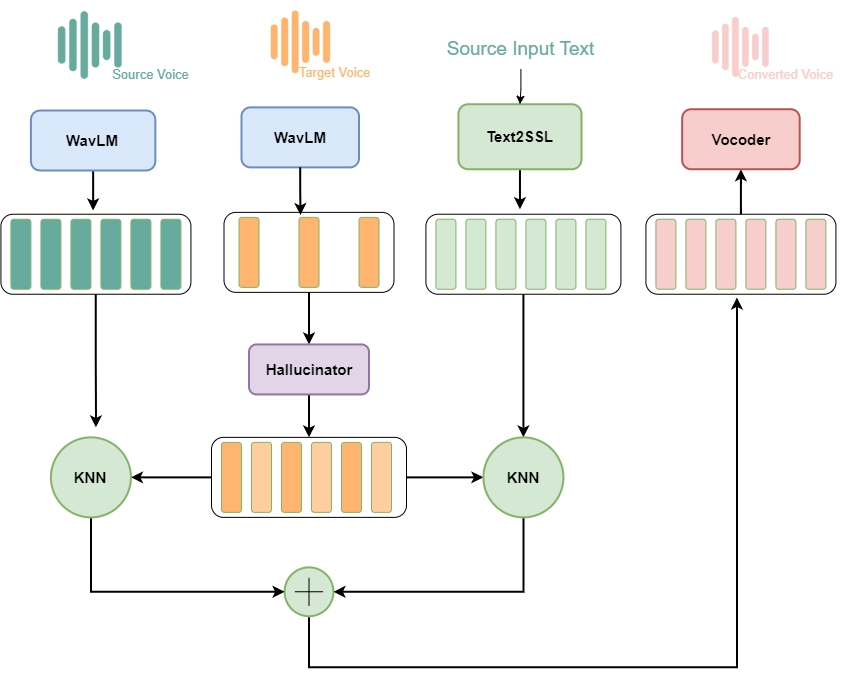
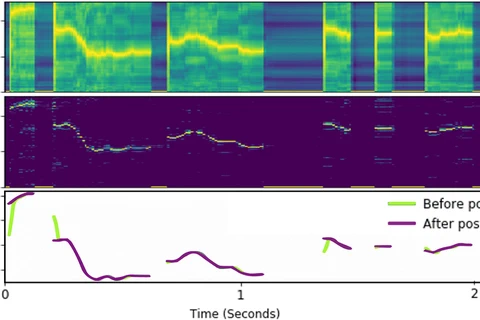
Postnet Layer
Generally speaking, the postnet layer receives a mel-spectrogram and predicts another mel-spectrogram with additional information. That makes the output mel-spectrogram more detail, and hence improves the quality of synthesis audio.
KNN-VC vs Phoneme Hallucinator [23/03/2024] ?
Overview
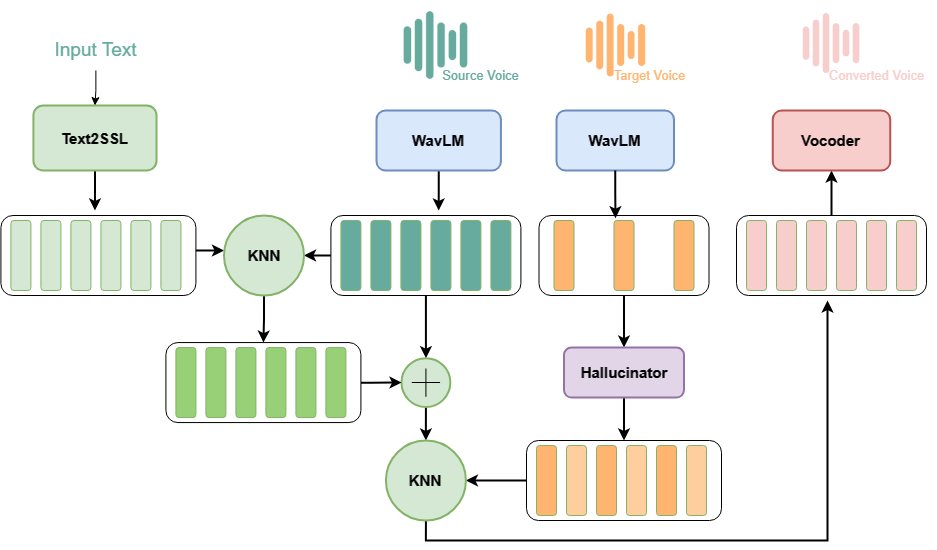
Comparing different methods
This section compares Phoneme Hallucinator kNN-VC and Phoneme Hallucinator.
| Source | Target | Phoneme Hallucinator | Phoneme Hallucinator + Text2SSL |
|---|---|---|---|
![KNN-VC vs Phoneme Hallucinator [23/03/2024] ?](/blog/speech-research/voice-conversion/voice-conversion-23-03-2024/featured_hu_6b2641e6dadf82bb.webp)
KNN-VC vs Phoneme Hallucinator [09/03/2024] ?
Overview
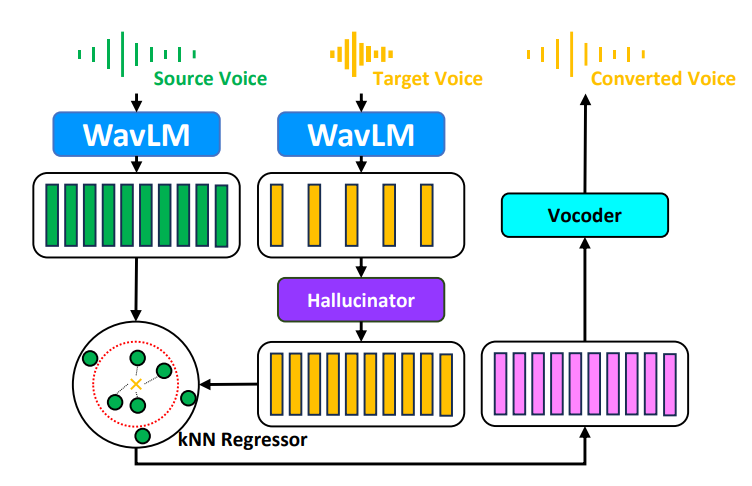
Comparing different methods
This section compares Phoneme Hallucinator kNN-VC and Phoneme Hallucinator.
| Source | Target | kNN-VC | Phoneme Hallucinator |
|---|---|---|---|
![KNN-VC vs Phoneme Hallucinator [09/03/2024] ?](/blog/speech-research/voice-conversion/voice-conversion-09-03-2024/featured_hu_8ddf655c243847ea.webp)
How to kill zombie processes using GPU ?
The trick for killing zombie processes using GPU in Linux 😃.
