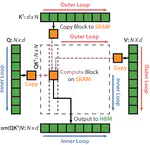
Overview Recently, OpenAI has just released the paper “Why Language Models Hallucinate” by Adam Tauman Kalai, Ofir Nachum, Santosh Vempala, and Edwin Zhang (2025).
Abstraction: Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty.