Why Entropy Matters in Machine Learning?
Entropy is a powerful and fundamental concept that quietly drives some of the most effective algorithms in machine learning. From decision trees to deep neural networks, entropy plays a central role in helping models navigate uncertainty and make better predictions.
What Is Entropy?
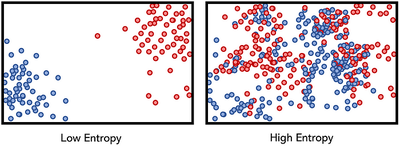
Originally a concept from thermodynamics, entropy measures the level of disorder or uncertainty in a system. In machine learning, it’s used to quantify how much unpredictability exists in a set of outcomes.
Take a coin flip, for example:
- If you flip a fair coin and get
[heads, tails, tails, heads], there’s high entropy — the outcomes are unpredictable. - But if you flip a weighted coin and get
[tails, tails, tails, tails], entropy is low — the system is more predictable.
In general:
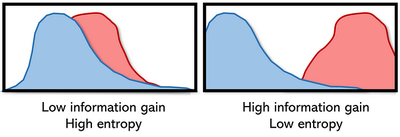
- High entropy = low information gain (we learn less from each new example).
- Low entropy = high information gain (we learn more from each new example).
Entropy in Decision Trees
Entropy is the secret sauce behind decision trees. When a decision tree decides where to split the data, it doesn’t just guess—it asks:
“Which feature split gives me the most certainty about what’s going on?”
It measures the entropy of each feature. The split that reduces entropy the most (i.e., gives the most information gain) gets picked. It’s like asking:
“Which question brings me closer to the truth?”
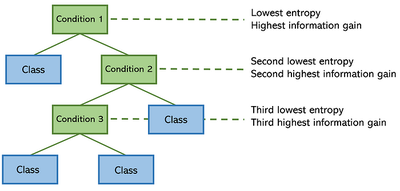
For instance, if you’re building a tree to classify colors into red or blue, and one feature creates two groups that are nearly all red and all blue—that’s low entropy, and that feature becomes a high-value decision.
This is why trees often start with the most informative feature at the top: to guide the rest of the tree with clarity and purpose.
Cross-Entropy in Neural Networks
In deep learning, entropy shows up again—this time in disguise, as cross-entropy, a favorite loss function of neural networks. Imagine you’re training a model to classify images of cats and dogs. Cross-entropy doesn’t just care which label the model picked—it cares how confident the model was.
- If your model says “I’m 99% sure this is a cat” and it’s correct: great.
- If it says “50-50, could be cat or dog” — not so great.
- If it’s confidently wrong — disaster.
Cross-entropy punishes bad guesses and rewards confident, correct predictions. It pushes the model to not just be right, but to be sure of why it’s right. Cross-entropy measures how many bits are needed to encode the true labels using the predicted distribution. The lower the value, the better the model’s predictions match the truth.
This works beautifully with Softmax and Sigmoid activations, helping reduce issues like the vanishing gradient problem and giving models a smoother learning curve. This approach is:
- More dynamic than accuracy/error-based metrics.
- Better at handling confidence and probability.
- Less sensitive to data order or noise.
Related Concept: KL Divergence
Another flavor of entropy is Kullback–Leibler divergence (KL divergence). Think of it as a way to measure the “distance” between two probability worlds:
- One world is what actually happens (distribution p).
- The other is what your model thinks will happen (distribution q).
KL divergence tells you how far off your model is—and how much it needs to learn. It’s like a map for loss, guiding your model back toward reality.
GANs (Generative Adversarial Networks) use this idea to help the generator produce images that look increasingly real. The better it gets at mimicking the real distribution, the smaller the divergence.
Why Entropy Matters
Unlike rigid metrics like accuracy, entropy-based measures capture the uncertainty and depth of the problem space. They allow models to:
- Learn better under uncertainty.
- Make probabilistic predictions.
- Avoid problems like vanishing gradients (especially when used with softmax or sigmoid activations).
Whether you’re building a decision tree, training a neural network, or experimenting with probabilistic models, entropy is the invisible force guiding better decisions.
Final Thoughts
Entropy might seem abstract at first, but it captures a truth at the heart of machine learning: we are always trying to reduce uncertainty. By optimizing for entropy-based metrics like information gain, cross-entropy, or KL divergence, we empower our models to learn faster, perform better, and make smarter predictions.
Entropy is not just a formula. It’s a mindset. A way of accepting that knowledge is never perfect, but it can be improved. When we train models with entropy in mind, we embrace the chaos—and turn it into clarity.