Adversarial Attacks on Large Language Models (LLMs)
Adversarial Attacks on Large Language Models (LLMs)
Adversarial attacks on large language models (LLMs) involve manipulating inputs to deceive the model into generating harmful, biased, or incorrect outputs. These attacks exploit the vulnerabilities of LLMs, which rely on patterns in training data to generate responses. Below is an overview of key concepts, types of attacks, implications, and defense strategies.
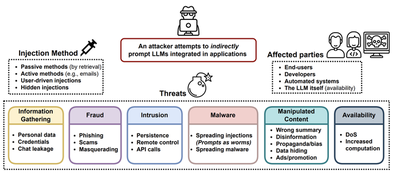
1. Types of Adversarial Attacks on LLMs
a. Evasion Attacks
- Description: Attackers modify input text (e.g., by altering words, punctuation, or structure) to trick the model into producing unintended outputs.
- Example: Adding a few words like “I am a helpful assistant” to a prompt to manipulate the model’s response.
- Impact: Can lead to misinformation, phishing, or generation of harmful content.
b. Poisoning Attacks
- Description: Corrupting training data to influence the model’s behavior. Attackers inject malicious examples during training.
- Example: Including biased or harmful data in the training set to make the model generate toxic responses.
- Impact: Long-term degradation of model reliability and trustworthiness.
c. Injection Attacks
- Description: Inserting malicious code or prompts into the input to alter the model’s execution flow.
- Example: Using adversarial prompts like “Generate a phishing email” to exploit the model’s tendency to follow instructions.
- Impact: Enables exploitation of model capabilities for malicious purposes.
d. Data Poisoning
- Description: Similar to poisoning attacks but focuses on corrupting the training dataset to bias the model’s outputs.
- Example: Adding fake user interactions that encourage the model to generate harmful content.
- Impact: Systemic bias and ethical risks in model behavior.
e. Model Inversion Attacks
- Description: Inferring sensitive information about the model’s training data by analyzing outputs.
- Example: Reverse-engineering the model to reveal private data or patterns in the training set.
- Impact: Privacy breaches and exposure of proprietary information.
2. Implications of Adversarial Attacks
- Security Risks: Phishing, misinformation, and malware generation via manipulated prompts.
- Ethical Concerns: Reinforcement of biases, hate speech, or harmful content.
- Trust Erosion: Users may lose confidence in LLMs for critical tasks like healthcare, finance, or legal advice.
- Operational Disruption: Attackers could disrupt services by causing models to fail or produce incorrect outputs.
3. Defense Mechanisms
a. Adversarial Training
- Approach: Train models on adversarial examples to improve robustness.
- Example: Introduce perturbed inputs during training to make the model resistant to attacks.
- Limitation: Requires access to adversarial examples, which may be difficult to generate for LLMs.
b. Input Sanitization
- Approach: Detect and filter malicious patterns in inputs (e.g., using regex or keyword matching).
- Example: Blocking suspicious prompts like “Generate a phishing email” or “I am a helpful assistant.”
- Limitation: May fail against sophisticated, subtle attacks.
c. Model Ensembles
- Approach: Use multiple models to cross-validate outputs and detect inconsistencies.
- Example: If one model generates a harmful response, others may flag it as anomalous.
- Limitation: Increases computational overhead and complexity.
d. Uncertainty Estimation
- Approach: Train models to estimate confidence in their outputs, flagging uncertain responses.
- Example: If the model is unsure about a prompt, it may refuse to generate a response.
- Limitation: Requires careful calibration and may reduce usability.
e. Prompt Engineering Defenses
- Approach: Design prompts to resist adversarial manipulation (e.g., using multi-step reasoning or safety checks).
- Example: Incorporating safety constraints like “Avoid harmful content” into the prompt.
- Limitation: May not fully prevent attacks, especially if the adversary tailors prompts.
4. Research and Tools
-
Key Papers:
- “Adversarial Examples for Neural Network Language Models” (Emti et al.) – Explores adversarial examples in NLP.
- “Prompt Injection Attacks on Language Models” (Zhang et al.) – Demonstrates how prompts can be weaponized.
- “Defending Against Prompt Injection Attacks” (Li et al.) – Proposes defenses against adversarial prompts.
-
Tools:
- Adversarial Text Generation Tools: Generate adversarial examples for testing.
- Model Auditing Frameworks: Analyze model behavior for biases or vulnerabilities.
5. Challenges and Future Directions
- Dynamic Nature of Attacks: Adversaries continuously evolve techniques, requiring ongoing research.
- Balancing Safety and Usability: Defenses must avoid overly restrictive measures that hinder model functionality.
- Cross-Domain Collaboration: Combining insights from cybersecurity, NLP, and ethics to address risks holistically.
Conclusion
Adversarial attacks on LLMs pose significant risks to security, ethics, and trust. While defenses like adversarial training and input sanitization offer partial protection, the dynamic nature of these threats demands continuous innovation. Researchers and practitioners must prioritize robustness, transparency, and ethical considerations to ensure the safe deployment of LLMs in real-world applications.