Understanding FlashAttention: Inner vs Outer Loop Optimization
Understanding FlashAttention: Inner vs Outer Loop Optimization
FlashAttention is a groundbreaking optimization technique for computing attention in Transformer models. It drastically improves performance by reducing memory bottlenecks and utilizing GPU memory more efficiently.
🚀 What Problem Does It Solve?
In traditional attention mechanisms:
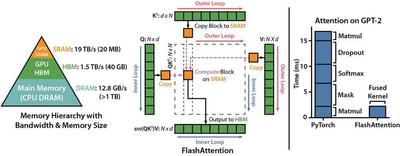
- Attention matrices like Q, K, and V are huge.
- GPU cores (CUDA cores) must fetch data from HBM (High Bandwidth Memory) repeatedly.
- Each access to HBM is slow and inefficient.
- Shared memory (SRAM) exists but is not optimally used.
This leads to frequent memory transfers, under-utilized cores, and slow inference time.
⚡ FlashAttention to the Rescue
FlashAttention solves this by:
- Dividing Q, K, V matrices into smaller blocks (e.g., 32x32).
- Copying each block from HBM to SRAM once (not repeatedly).
- Performing all computations inside SRAM, near the GPU cores.
- Writing results back to HBM only once per block.
This dramatically reduces memory access overhead and accelerates attention computations.
🔁 Inner Loop vs Outer Loop
Outer Loop
- Responsible for loading blocks of K/V from HBM to SRAM.
- Each iteration handles a large memory transfer.
- Runs infrequently but handles heavy data movement.
Inner Loop
- Executes on the data already in SRAM.
- Performs matrix multiplications (Q×Kᵀ), softmax, and QK×V.
- Runs frequently but operates on fast-access memory.
- Fast and efficient — no further HBM access needed.
🧠 Analogy: Kitchen Example
- HBM = Warehouse far away.
- SRAM = Workbench in your kitchen.
- Outer loop = You bring a tray of ingredients from warehouse to your kitchen.
- Inner loop = You cook the full meal using what’s already on your workbench.
Traditional attention = you run back to the warehouse for every spoon of spice 😅
FlashAttention = bring the whole spice rack once, cook in peace! 👨🍳
✅ Summary
| Feature | Traditional Attention | FlashAttention |
|---|---|---|
| Memory Access | Frequent HBM access | One-time block transfer |
| SRAM Usage | Under-utilized | Fully utilized per block |
| Computation Location | Mix of HBM and registers | All in SRAM |
| Speed | Slower, memory bottleneck | Much faster, memory-efficient |
FlashAttention is a key breakthrough for making large models faster and more scalable — especially during inference.