GLiNER: A Generalist Model for Named Entity Recognition using Bidirectional Transformers
1. What is Named Entity Recognition (NER)?
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that involves identifying and classifying spans of text that refer to real-world entities such as:
- Persons (e.g., “Albert Einstein”),
- Organizations (e.g., “United Nations”),
- Locations (e.g., “Paris”),
- Dates, Products, Diseases, and many more.
Traditional NER systems are trained on a fixed set of entity types, which limits their adaptability to new domains or tasks. Recently, Open NER has emerged as a flexible paradigm that allows recognizing arbitrary entity types based on natural language instructions — a direction GLiNER directly embraces and enhances.
2. Overview
GLiNER is a compact and general-purpose model for Named Entity Recognition (NER) that leverages Bidirectional Transformers (like BERT or DeBERTa) to extract arbitrary types of entities from text — without being constrained to a fixed label set. Unlike traditional NER models or large language models (LLMs) like ChatGPT, GLiNER is lightweight, efficient, and designed for zero-shot generalization across domains and languages.
Traditional NER systems are limited by a fixed ontology of entity types. While LLMs (e.g., GPT-3, ChatGPT) allow open-type NER via prompting, they are computationally expensive, slow (token-by-token decoding), and often impractical in production due to API cost and latency. GLiNER aims to:
- Retain the flexibility of LLMs in handling arbitrary entity types.
- Achieve high performance with orders of magnitude fewer parameters.
- Enable parallel extraction of entities rather than autoregressive generation.
3. Model Architecture
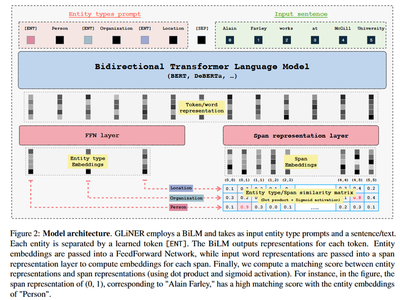
GLiNER reframes NER as a semantic matching problem between entity types and text spans in a shared latent space.
-
Input Format:
[ENT] person [ENT] organization [ENT] location [SEP] Text... - `[ENT]`: special token preceding each entity type. - `[SEP]`: separates entity types from input text. -
Bidirectional Encoder: A BiLM (e.g., DeBERTa-v3) encodes both entity types and the input text.
-
Span Representation Module: Computes span embeddings from token representations using a feedforward network: \[ S_{ij} = \text{FFN}(h_i \oplus h_j) \]
-
Entity Representation Module: Processes entity type embeddings via another FFN.
-
Matching Layer: Calculates matching score: \[ \phi(i, j, t) = \sigma(S_{ij}^T q_t) \] where $\sigma$ is the sigmoid function.
-
Training Strategy
- Objective: Binary cross-entropy loss over span/type pairs.
- Data Source: Trained on Pile-NER, a dataset derived from The Pile corpus with 44.8k passages and 13k entity types. Labels were generated by ChatGPT, acting as a teacher model (data-level distillation).
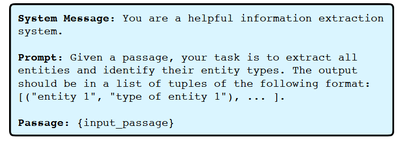
Prompting ChatGPT for entity extraction in Pile-NER dataset - Techniques for robustness:
- Negative sampling of entity types.
- Random shuffling and dropping of entity prompts.
- Span length cap (max 12 tokens) for efficiency.
4. Experimental Results
-
For zero-shot evaluation, on 20 diverse NER benchmarks and out-of-domain (OOD) tasks,
GLiNER-L (0.3B)outperforms: ChatGPT, InstructUIE (11B), UniNER (13B) and even GoLLIE (7B) in most cases. -
For multilingual performance without multilingual training:
GLiNER-Multi (mDeBERTa)surpasses ChatGPT on 8 out of 11 languages (e.g., Spanish, German, Russian). which shows strong generalization, even on unseen scripts. -
With supervised fine-tuning, after fine-tuning on labeled datasets, GLiNER competes closely with or surpasses InstructUIE, performs nearly as well as UniNER (larger LLaMA-based model). Pretraining on Pile-NER improves data efficiency, especially with small datasets.
-
Efficiency and Scalability
- GLiNER allows parallel inference for multiple entity types.
- Training Time: ~5 hours on a single A100 GPU for GLiNER-L.
- Parameter Sizes: 50M (S), 90M (M), 300M (L), compared to 7B–13B in baselines.
5. Ablation Insights
| Component | Effect |
|---|---|
| Negative sampling (50%) | Best F1 balance |
| Dropping entity types | +1.4 F1 on OOD datasets |
| deBERTa-v3 backbone | Outperforms RoBERTa, BERT, ALBERT, ELECTRA |
- Earlier NER approaches include rule-based systems, sequence labeling (e.g., BiLSTM-CRF), and span classification.
- LLM-based models (e.g., InstructUIE, UniNER) use instruction-tuning or generation.
- GLiNER offers a middle ground: lightweight yet capable of open-type NER.
6. Conclusion
GLiNER is a generalist, scalable, and high-performing model for Named Entity Recognition that:
- Bridges the gap between classic NER and large LLM-based models.
- Achieves state-of-the-art zero-shot results with minimal resources.
- Demonstrates robust multilingual and cross-domain generalization.
This makes it an excellent candidate for real-world NER applications in low-resource, high-efficiency environments.
🔗 Code: https://github.com/urchade/GLiNER
📄 Paper: Urchade Zaratiana et al., GLiNER: Generalist Model for Named Entity Recognition using Bidirectional Transformer, arXiv:2311.08526