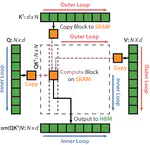
Understanding FlashAttention: Inner vs Outer Loop Optimization FlashAttention is a groundbreaking optimization technique for computing attention in Transformer models. It drastically improves performance by reducing memory bottlenecks and utilizing GPU memory more efficiently.