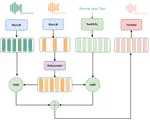
Overview This thesis develops a voice conversion model for Vietnamese based on the Phoneme Hallucinator model with 2 adoptions: (1) Add a Text2SSL module to get more context information before performing the KNN algorithm, (2) To create a more
diverse dataset we apply spectrogram-resize (SR) based data augmentation idea from Free-VC model which distorts speaker information without changing content information to generate more ”speakers”.
![KNN-VC vs Phoneme Hallucinator [09/03/2024] ?](/post/speech-research/voice-conversion/voice-conversion-09-03-2024/featured_hu247d5b7fd5c49ebd144b6f04e075f068_52595_150x0_resize_q75_h2_lanczos_2.webp)
![KNN-VC vs Phoneme Hallucinator [23/03/2024] ?](/post/speech-research/voice-conversion/voice-conversion-23-03-2024/featured_hu9c2c2c0b1c61256ebe168fc02f8de765_124214_150x0_resize_q75_h2_lanczos_2.webp)